
Hadoop: The Backbone of Big Data
In the era of big data, vast amounts of information are generated every second. Traditional data processing tools cannot manage or analyze such enormous datasets. This is where Hadoop, an open-source framework, steps in. Hadoop has revolutionized the way businesses and organizations handle big data, offering a robust, scalable, and cost-effective solution. This article delves deep into the world of Hadoop. It explores its architecture and key components. It also covers its applications and the future of this groundbreaking technology.
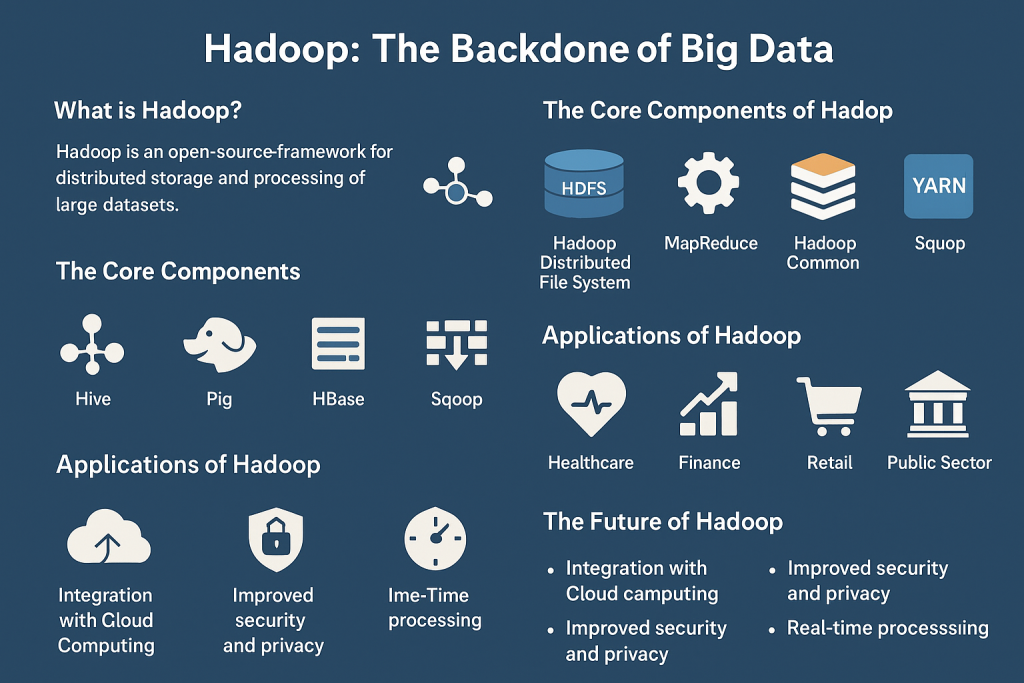
1. What is Hadoop?
Hadoop is an open-source software framework that enables the distributed storage and processing of large datasets across clusters of computers. Doug Cutting and Mike Cafarella developed Hadoop in 2006. It was inspired by Google’s MapReduce and Google File System (GFS). Hadoop was designed to handle data at a scale that traditional databases couldn’t manage. It is part of the Apache Software Foundation and has become a cornerstone of the big data ecosystem.
2. The Core Components of Hadoop
Hadoop consists of four primary components, each playing a critical role in the framework’s functionality:
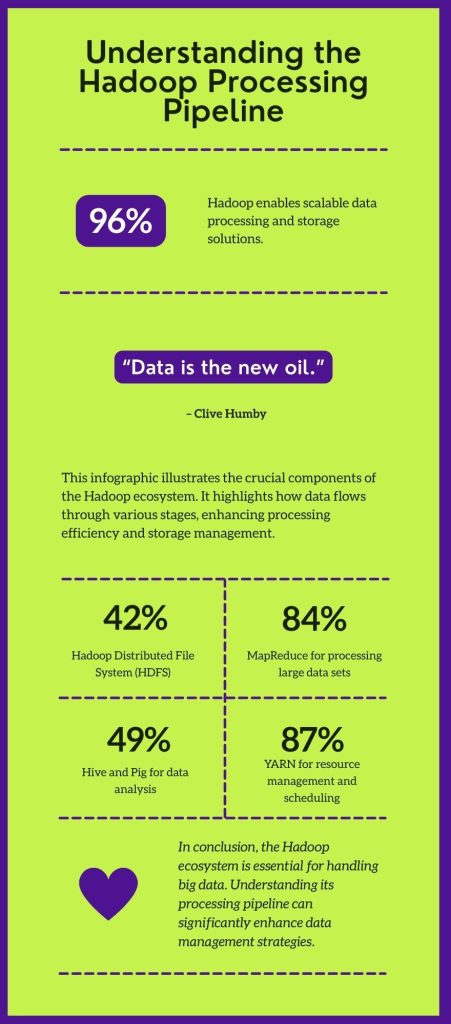
2.1 Hadoop Distributed File System (HDFS)
HDFS is the storage system of Hadoop. It is designed to store very large datasets reliably. It streams those datasets at high bandwidth to user applications. HDFS breaks down files into blocks and distributes them across a cluster of nodes, ensuring fault tolerance and high availability.
– Block Storage: HDFS stores data in blocks (typically 128 MB each), distributed across multiple nodes in a cluster.
– Fault Tolerance: HDFS automatically replicates blocks across different nodes, providing redundancy in case of hardware failures.
– Scalability: HDFS can scale out horizontally, adding more nodes to handle larger datasets.
2.2 MapReduce
MapReduce is the processing engine of Hadoop, allowing for the distributed processing of large datasets across a Hadoop cluster. It breaks down tasks into smaller sub-tasks (map), processes them in parallel, and then combines the results (reduce).
– Mapping: Data is divided into key-value pairs and processed in parallel across the cluster.
– Reducing: The intermediate outputs are aggregated to produce the final result.
– Parallel Processing: MapReduce enables efficient processing of large-scale data by distributing tasks across multiple nodes.
2.3 Hadoop Common
Hadoop Common provides the essential libraries and utilities needed by other Hadoop modules. It includes a set of utilities for the configuration, management, and monitoring of the Hadoop framework.
– Libraries: Essential Java libraries and scripts that support other Hadoop components.
– Configuration Management: Tools for configuring and managing the Hadoop ecosystem.
– Cluster Management: Utilities for maintaining and monitoring the health of the Hadoop cluster.
2.4 YARN (Yet Another Resource Negotiator)
YARN is the resource management layer of Hadoop. It is responsible for allocating system resources to different applications running in the Hadoop cluster.
– Resource Allocation: Manages and allocates resources like CPU, memory, and storage to various tasks.
– Job Scheduling: Ensures efficient execution of tasks by scheduling jobs across the cluster.
– Scalability: YARN can handle thousands of nodes and is designed to scale horizontally.
3. The Hadoop Ecosystem
Beyond its core components, Hadoop is part of a broader ecosystem of tools and technologies designed to enhance its capabilities. Some key tools in the Hadoop ecosystem include:
3.1 Hive
Hive is a data warehousing tool. It enables users to query and manage large datasets stored in HDFS. This is done using a SQL-like language called HiveQL.
– SQL-Like Queries: Hive allows users to write queries comparable to SQL. This makes it accessible to those familiar with traditional relational databases.
– Data Warehousing: Hive supports data aggregation, summarization, and analysis, making it ideal for business intelligence tasks.
– Compatibility: Hive integrates seamlessly with other Hadoop components and supports multiple data formats.
3.2 Pig
Pig is a high-level scripting language used for data processing tasks. It provides a simpler option to writing complex MapReduce programs.
– Pig Latin: The scripting language of Pig, designed to simplify data processing tasks.
– Data Transformation: Pig is ideal for tasks like data cleansing, filtering, and transformation.
– Ease of Use: Pig scripts are more concise and easier to write than traditional MapReduce code.
3.3 HBase
HBase is a distributed, scalable, NoSQL database that runs on top of HDFS. It is designed for real-time read/write access to large datasets.
– Column-Oriented Storage: HBase stores data in a column-oriented format, making it efficient for read/write operations.
– Scalability: HBase can handle billions of rows and millions of columns, making it ideal for large-scale data storage.
– Real-Time Processing: HBase supports real-time data processing, making it suitable for applications requiring immediate data access.
3.4 Sqoop
Sqoop is a tool designed for transferring data between Hadoop and relational databases.
– Data Import/Export: Sqoop simplifies the process of importing data from SQL databases into Hadoop. It also simplifies exporting processed data back to the databases.
– Efficiency: Sqoop parallelizes data transfer tasks, making them faster and more efficient.
– Compatibility: Sqoop supports all major relational databases, including MySQL, Oracle, and PostgreSQL.
3.5 Flume
Flume is a distributed service. It collects, aggregates, and moves large amounts of log data. The data comes from various sources and transfers to a centralized data store like HDFS.
– Log Data Ingestion: Flume is designed to handle large volumes of log data. This capability makes it ideal for real-time data analysis.
– Reliability: Flume ensures data is reliably delivered, even if node failures occur.
– Scalability: Flume can scale horizontally, handling increasing amounts of data by adding more agents.
4. Applications of Hadoop
Hadoop’s versatility makes it applicable across various industries and use cases:
4.1 Healthcare
Hadoop is used to store and analyze vast amounts of healthcare data, enabling predictive analytics and personalized medicine.
– Predictive Analytics: Hospitals use Hadoop to predict patient outcomes and optimize treatment plans.
– Genomic Data Processing: Hadoop helps in processing and analyzing large-scale genomic data for research and personalized treatment.
– Healthcare Fraud Detection: Hadoop’s ability to process large datasets helps in detecting fraudulent activities in healthcare systems.
4.2 Finance
In the financial sector, Hadoop is used to manage large datasets for risk management. It is also used for fraud detection and algorithmic trading.
– Risk Management: Banks use Hadoop to assess risk by analyzing historical and real-time data.
– Fraud Detection: Hadoop’s scalability allows it to process deal data in real-time, helping to detect fraudulent activities quickly.
– Algorithmic Trading: Hadoop enables the analysis of large datasets to develop trading algorithms that can respond to market changes.
4.3 Retail
Retailers leverage Hadoop to gain insights into customer behavior, optimize supply chains, and enhance the overall shopping experience.
– Customer Insights: Retailers analyze customer data using Hadoop to create personalized marketing campaigns and improve customer satisfaction.
– Supply Chain Optimization: Hadoop helps retailers manage and optimize their supply chains by analyzing inventory, sales, and logistics data.
– Recommendation Engines: Retailers use Hadoop to power recommendation engines, offering personalized product suggestions to customers.
4.4 Public Sector
Government agencies use Hadoop to analyze large datasets for policy-making, public safety, and resource allocation.
– Policy Analysis: Hadoop enables governments to analyze data from various sources to make informed policy decisions.
– Public Safety: Hadoop is used to analyze crime data, helping law enforcement agencies predict and prevent criminal activities.
– Resource Allocation: Government agencies use Hadoop to optimize resource allocation by analyzing data on population, infrastructure, and services.
5. The Future of Hadoop
Hadoop has come a long way since its inception, but its future continues to evolve. As the big data landscape changes, Hadoop is adapting to new challenges and opportunities:
5.1 Integration with Cloud Computing
The integration of Hadoop with cloud computing platforms like AWS, Google Cloud, and Azure is becoming increasingly popular. Cloud-based Hadoop solutions offer scalability, flexibility, and cost-efficiency. They make it easier for organizations to manage and analyze big data. This all happens without the need for extensive on-premises infrastructure.
5.2 Improved Security and Privacy
Data privacy regulations like GDPR and CCPA are becoming more stringent. In response, Hadoop is evolving to include more robust security and privacy features. Future versions of Hadoop will likely focus on enhanced data encryption, access controls, and compliance with global data protection standards.
5.3 Real-Time Data Processing
While Hadoop has traditionally been linked to batch processing, there is a growing demand for real-time data processing capabilities. With the integration of tools like Apache Kafka and Apache Flink, Hadoop is moving towards supporting real-time data streams
Leave a Reply